Deep Learning 은 인간의 뇌에서 영감을 받은 인공 신경망을 사용하여 컴퓨터가 학습하는 머신 러닝 의 방법 중 하나로, 음악을 만들거나, 우리가 오렌지와 사과를 보고 각각 다른 과일이라고 인식할 수 있는 것 처럼 컴퓨터가 사진이나 사물을 보고 이해할 수 있거나 언어를 이해하는 방법을 학습 하는 것이라고 정의할 수 있습니다. ‘Deep’ 이라는 단어는 신경망에 여러 층(레이어)을 쌓아 깊게 만든다는 의미입니다. 이러한 깊은 네트워크를 통해 컴퓨터는 복잡한 문제를 해결하는 데 필요한 패턴이나 관계를 스스로 찾아낼 수 있습니다. 딥러닝은 이미지 인식, 음성 인식, 자연어 처리 등 다양한 분야에서 활용되고 있습니다.
Deep Learning (딥 러닝) 의 개념
간략히 딥러닝의 역사를 살펴보면, 가장 초기의 인공 신경망인 퍼셉트론(Perceptron)이 1958년에 제안되었습니다. 이후 1986년에 다층 퍼셉트론(Multilayer Perceptron)이 제안되고, 이를 학습시키는 방법인 역전파(Backpropagation) 알고리즘이 등장하면서 딥러닝의 기초가 마련되었습니다.
퍼셉트론은 간단한 문제를 해결하는 컴퓨터의 작은 뇌(Brain)와 같습니다. 모아진 퍼셉트론은 복잡한 문제도 해결할 수 있게 되는데, 이것이 바로 딥러닝, 즉 ‘깊은 학습’입니다. 인간의 뇌에는 “뉴런(Neuron)” 이 수억 개 있고, 이들이 함께 작동하여 생각하고, 느끼고, 기억하는 데 도움을 줍니다. 퍼셉트론은 이런 뉴런을 모방한 것으로, 간단한 계산을 수행하고 문제를 해결합니다.
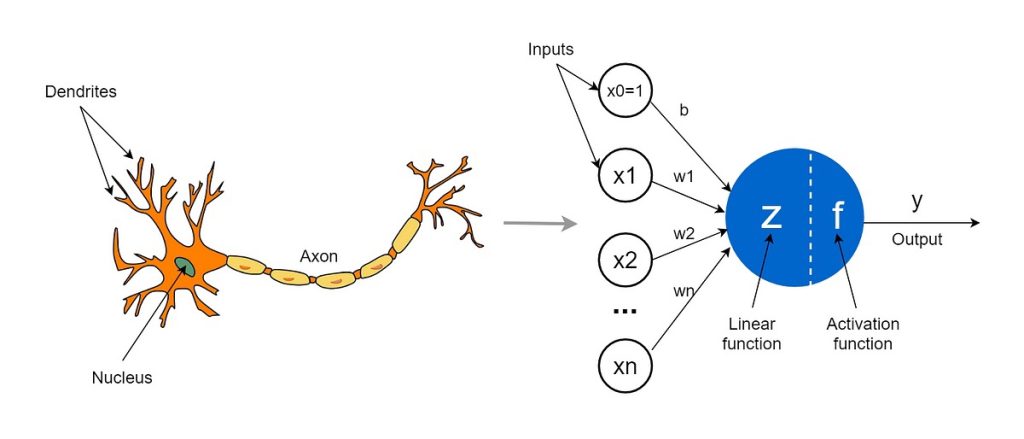
뉴런은 덴드라이트(작은 섬유)를 통해 다른 뉴런으로부터 입력 신호를 받습니다. 마찬가지로, 퍼셉트론은 숫자를 받는 입력 뉴런을 통해 다른 퍼셉트론으로부터 데이터를 받습니다. 생물학적 뉴런에서, 출력 신호는 축삭에 의해 운반 됩니다. 마찬가지로, 퍼셉트론의 축삭은 다음 퍼셉트론의 입력이 될 출력 값 입니다. 덴드라이트와 생물학적 뉴런 사이의 연결 지점은 “시냅스” 라고 정의 합니다. 입력과 퍼셉트론 사이의 연결은 ”가중치“ 라고 정의 합니다. 그들은 각 입력의 중요성 수준을 측정 할 수 있는 지표가 됩니다. 뉴런에서, 핵은 덴드라이트가 제공하는 신호를 기반으로 출력 신호를 생성 합니다. 마찬가지로, 퍼셉트론의 핵(파란색)은 입력 값을 기반으로 몇 가지 계산을 수행하고 출력을 생성합니다.

딥러닝 개념이 시작한 초기에는 컴퓨터의 성능이 부족하여 복잡한 신경망을 학습시키기 어려웠습니다. 2000년대 초반에 들어서 GPU가 발전하고 빅 데이터가 확산되면서 딥러닝은 크게 주목받게 되었습니다. 이 중 2012년에 딥러닝 모델인 AlexNet이 이미지 인식 대회에서 우승하면서 딥러닝은 성능을 인정받게 되었습니다.
2016년에 세계 챔피언 이세돌 9단과 바둑 대국에서 승리하면서 전 세계적으로 주목 받았던 알파고는 Google의 딥마인드(DeepMind) 팀이 개발한 딥러닝과 강화학습 으로 탄생한 기술 입니다. 딥러닝은 바둑판의 상태를 해석하고 다음 수를 예측하는 데 사용되었고 강화학습은 알파고가 자기 자신과 게임을 하면서 수천만 개의 바둑 기보를 분석하고 스스로 학습하느여 어떤 수가 승리에 이르는 방법을 학습하여 바둑의 복잡성을 이해하고, 강화학습을 통해 전략을 최적화하여 인간과 바둑을 둘 수 있게 되었습니다.
딥러닝은 이미지 분석, 음성 인식, 자연어 처리 등 다양한 분야에서 뛰어난 성능을 보이며 머신러닝 분야의 주요한 연구 방향이 되고있습니다.